RAG·LLM 전처리의 시작, 한컴 데이터 로더 문서 파싱 솔루션- AI 학습 데이터로의 변환

한컴 데이터 로더(Hancom Data Loader)는 한컴이 개발한 문서 구조 분석(Document Parsing) 솔루션입니다. HWP·HWPX·PDF·OOXML을 AI가 이해할 수 있도록 도와주는 RAG 기반 AI 학습에 특화된 문서 데이터 전처리 기술입니다.
에이전트가 움직이기 전에 문서를 이해 가능한 AI 데이터로 변환해주는 한컴 데이터 로더는 의미 단위까지 분리·추출해 에이전트 친화적 메타데이터로 제공합니다.
기업 AI 도입 시 문서 데이터화는 왜 어려울까?
대규모 언어 모델(LLM)이 PDF·HWP·HWPX 같은 내부 문서를 그대로 읽지 못하기 때문이에요.
사내 AI 어시스턴트·검색 증강 생성(RAG)·에이전트 도입을 검토하는 공공기관·대기업 DX조직·SI 파트너가 공통으로 부딪히는 벽이 바로 이 비정형 문서 처리입니다.
문서 데이터 구조화가 필요한 이유 – LLM과 비정형 문서의 간극
기업은 매뉴얼·보고서·계약서·HWP·HWPX 공문 등 방대한 자료를 갖고 있지만 LLM이 그대로 활용할 수 있는 형태의 자료는 많지 않습니다.
PDF는 표·다단·캡션 구조가 사라지고, HWP·HWPX는 단순 텍스트 추출만으로는 의미가 깨집니다. 표 행·열이 뒤섞이고 그럴듯한 요약 뒤에 근거가 사라지는 답변이 나오는 이유입니다. 문서를 구조화 데이터로 변환해야 LLM이 사내 정보를 제대로 읽을 수 있습니다.
RAG 파이프라인에서 문서 파싱 품질이 중요한 이유
AI 전환(AX)을 추진하는 조직에서 구조화된 문서 데이터는 검색을 넘어 에이전트 판단·실행 신뢰도까지 좌우하는 자산입니다.
RAG 파이프라인에서 문서 전처리 품질이 검색·판단·실행 전체를 결정하기 때문입니다.
파싱 단계에서 표 구조가 손실되면 관련 없는 텍스트가 섞이고, 임베딩 단계에서 잘못된 위치에 매핑될 수 있습니다.

문서 구조 분석 파싱 솔루션, 한컴 데이터 로더 – 정의와 핵심 역할
한컴 데이터 로더, 문서 구조 분석 자동화 솔루션
한컴 데이터 로더는 한컴이 개발한 문서 구조 분석(Document Parsing) 솔루션입니다. HWP·HWPX·PDF·OOXML 등 다양한 형식의 문서를 AI가 이해할 수 있는 구조화 데이터로 변환하며, RAG 기반 지식 검색 시스템 구축, 대규모 언어 모델(LLM) 학습 데이터 확보, 기업 문서 디지털화에 활용할 수 있습니다.
OCR(Optical Character Recognition, 광학 문자 인식) 기반 추출을 포함해 표·제목·캡션·계층 구조 등 문서의 의미 단위까지 분리·추출해 에이전트 친화적 메타데이터로 제공하고 있습니다. 일반 OCR이 아닌 문서 구조 보존형 추출 방식으로, RAG 구축의 핵심 전처리 기술로 자리잡고 있습니다.
문서 분석은 문서 구조 분석(DLA, Document Layout Analysis)·OCR·표 구조 인식(TSR, Table Structure Recognition) 기반으로 수행되며, 텍스트·표·이미지 등 문서 구성 요소를 구분하고 구조 정보를 함께 추출합니다. 단순 텍스트 추출을 넘어 문서 내 의미 단위를 분리하고 메타데이터 형태로 제공하는 것이 특징입니다.
또한 HWP·HWPX 문서는 문단 기반의 계층 구조 정보를 제공하며, PDF_AI는 이미지 캡셔닝(Image Captioning) 기반의 시각 정보 해석 기능을 지원합니다.
(※ 이미지 캡셔닝 기능은 현재 PoC 단계로, 상용 출시 일정은 추후 안내될 예정입니다.)
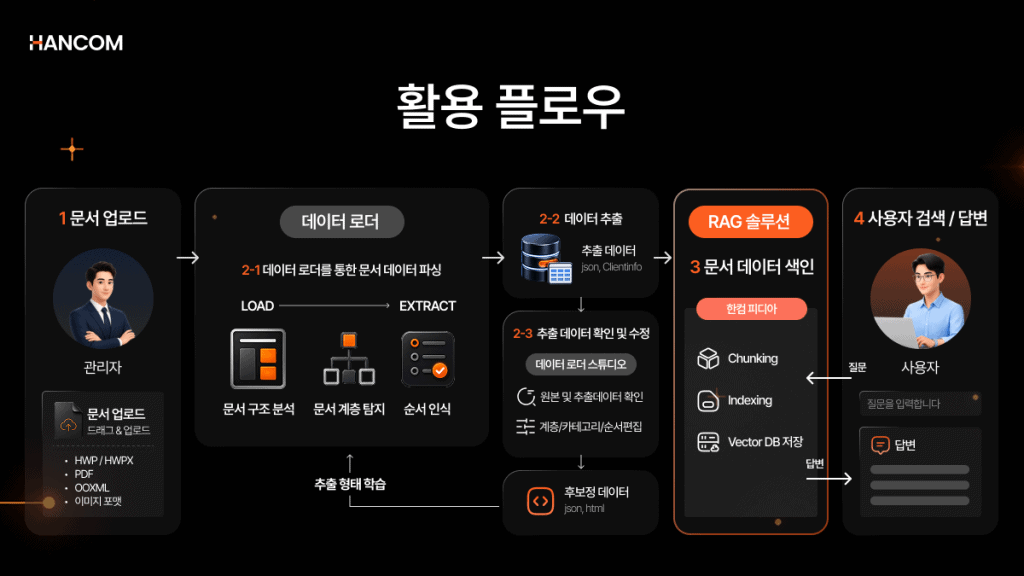
문서 구조 분석부터 데이터 추출까지
한컴 데이터 로더는 문서 입력 → 문서 분석 → 데이터 추출의 3단계 처리 흐름으로 구조화 데이터를 생성해요. 추출된 데이터는 이후 RAG 파이프라인·LLM과 연계해 AI 서비스 구축에 활용할 수 있습니다.
또한, 문서 분석 단계에서는 규칙 기반 분석과 AI 기반 문서 구조 이해 두 엔진을 함께 병행하고 있어요. 형식이 일정한 정형 문서는 규칙 기반으로 처리하고, 그림·표·이미지가 혼합된 비정형 문서는 AI 기반으로 정밀하게 분석하죠.
다양한 문서 요소를 인식하고 다단 읽기 순서를 탐지하며, 복잡한 표·차트 구조를 추출하는 등 문서 전처리 과정에서 필요한 핵심 기능을 하나의 처리 흐름으로 제공합니다.
추출된 구조화 데이터는 한컴의 자체 RAG 솔루션 한컴피디아와 직접 연계가 가능해, 문서 기반 AI 검색 시스템을 빠르게 구축할 수 있습니다.

문서 데이터 추출 대상 – 다양한 문서 포맷 지원
공공기관 AI 도입의 핵심 포맷 지원 – HWP·HWPX 파싱
정부가 2026년부터 HWPX 사용 확대와 HWP 첨부 단계적 제한을 추진하면서, HWP·HWPX 완전 지원은 공공 AI 도입의 필수 조건이 되고 있습니다.한컴 데이터 로더는 HWP 3.0 이상 전 버전을 지원하며, 한컴이 직접 만든 파서로 PDF 변환 없이 약 20종 이상 레이아웃 요소를 손실 없이 보존합니다.
범용 모든 포맷 문서 지원 – PDF·OOXML(DOCX·XLSX·PPTX)
PDF(AI)는 문서 구조 분석(DLA)·표 구조 인식(TSR)·OCR을 통해 레이아웃 분석과 표 구조 복원까지 처리하며, 스캔 문서도 OCR 연동으로 데이터 손실을 최소화합니다. OOXML(DOCX·XLSX·PPTX)은 텍스트 추출 방식으로 오피스 문서 내 텍스트를 추출합니다.
비정형 시각 문서 – PNG·JPG
PNG·JPG는 텍스트와 레이아웃을 자동으로 인식해 팩스 문서·스캔 이미지·사진 문서 등 디지털화되지 않은 자료까지 데이터화합니다.
한컴 데이터 로더 핵심 기능 – 문서 구조 분석(DLA)·표 구조 인식(TSR)·OCR 기반 문서 구조 분석
문서 구조 분석(DLA) – 메타데이터까지 추출하는 AI 기반 구조 분석
한컴 데이터 로더의 문서 구조 분석(DLA)은 카테고리로 객체를 분류하고 표·각주·이미지·차트·캡션·수식·글꼴까지 메타데이터로 추출합니다.
메타데이터가 함께 추출되면 RAG 검색 정확도가 올라가 정책 검색·행정 QA·내부 지식 에이전트가 신뢰도 높은 데이터를 활용할 수 있습니다.
표·이미지·차트 구조 인식 – 비정형 데이터 처리의 핵심 표 구조 인식(TSR) 기술
기업 문서의 핵심 정보는 본문보다 표·차트에 집중되는 경우가 많습니다. 한컴 데이터 로더는 표 구조 인식(TSR) 기반으로 테두리 없는 표, 병합 셀, 표 안의 표까지 셀 관계를 복원해 마크다운·HTML로 변환하며, 다단 레이아웃 보존으로 AI 결과 품질을 높입니다.
데이터 분리 및 후보정 – 데이터 로더 스튜디오
자동 추출만으로 정확도를 확보하기 어려운 문서를 위해 데이터 로더 스튜디오(확장 솔루션)를 제공합니다. 데이터 로더로 전처리한 추출 결과는 원본 문서와 나란히 비교하며 검토할 수 있으며, 사용자는 계층·카테고리·읽기 순서 등을 직접 확인하고 필요한 부분을 후보정해 문서 구조와 의미 관계가 실제 업무 목적에 맞게 정제되도록 관리할 수 있습니다. 또한 의미 기반 태깅과 라벨링 작업을 통해 고객사 문서 양식에 맞는 추출 기준을 보완하고, 학습 및 검색에 적합한 데이터 품질로 다듬을 수 있습니다.
문서 기반 AI의 시작점, 한컴 데이터 로더
🖥️한컴 데이터 로더
한컴 데이터 로더는 HWP·HWPX·PDF·OOXML을 구조화 데이터로 전환하는 문서 파싱(Document Parsing) 솔루션입니다. 추출된 데이터는 자사 RAG 솔루션 한컴피디아와 연계해 문서 수집부터 검색·답변까지 한컴 단일 스택으로 구축할 수 있습니다. 에이전트가 신뢰할 수 있는 문서 전처리, 한컴 데이터 로더로 시작해 보세요.
참고자료
1) 연합뉴스, 「”AI 못 읽는 hwp 줄인다”…정부, 개방형 hwpx로 전환」, 2026
