VLM이란? Vision Language Model 개념부터 문서 AI 활용까지 쉽게 이해하기

영수증 사진을 찍어 AI에게 보여줬을 때 금액을 바로 읽어내거나, 계약서 이미지에서 핵심 조항을 요약해주는 경험, 해보신 적 있으신가요?
이런 기능의 핵심 기술이 바로 VLM(Vision-Language Model, 시각 언어모델)입니다. 이미지와 텍스트를 함께 이해하는 멀티모달 AI 기술로 입니다. 이미지와 텍스트를 함께 이해하는 멀티모달 AI 기술로, 최근 문서 처리 분야에서 빠르게 주목받고 있습니다. 이번 글에서는 VLM이 무엇인지, OCR(Optical Character Recognition, 광학 문자 인식) ·LLM(Large Language Model, 대규모 언어 모델)과 어떤 차이가 있는지, 그리고 RAG 파이프라인과는 어떻게 연결되는지 쉽게 정리해보겠습니다.

VLM이란 무엇인가
VLM(Vision-Language Model, 시각 언어모델)의 기본 개념
VLM은 이미지와 텍스트를 함께 처리하는 멀티모달 AI 모델입니다.
기존 LLM은 텍스트만 입력받아 처리하는 구조예요. 문서를 넣으면 글자로 된 정보만 읽을 수 있고, 그 안에 포함된 이미지나 차트는 의미 있는 데이터로 이해하지 못합니다.
VLM은 여기서 한 단계 더 나아가, 비전 인코더(Vision Encoder)가 이미지를 벡터로 변환한 뒤 LLM과 함께 처리하는 구조예요. 텍스트뿐 아니라 시각 정보까지 하나의 입력으로 받아 의미와 맥락을 함께 이해합니다.
예를 들어 매출 그래프 이미지를 입력하면, LLM은 이미지를 읽지 못하지만 VLM은 “3분기 매출이 전분기 대비 상승한 막대그래프“라고 해석할 수 있습니다.
대표적인 모델로는 LLaVA, Qwen, Gemma가 있으며, 이미지 캡셔닝(Image Captioning) , 시각적 질문 답변(VQA), 문서 이해에 활용되고 있습니다.
VLM이 이미지와 텍스트를 이해하는 방식
VLM은 이미지 입력 → 비전 인코더 → 이미지 토큰 변환 → LLM 처리 → 텍스트 생성의 흐름으로 작동합니다.
이미지가 입력되면 비전 인코더(Vision Encoder)가 시각적 특징을 추출합니다. 추출된 특징은 프로젝터(Projector)를 거쳐 LLM이 처리할 수 있는 이미지 토큰(Image Token) 형태로 변환됩니다.
이후 텍스트 질문과 함께 LLM에 입력되어 최종 자연어 답변이 생성됩니다.

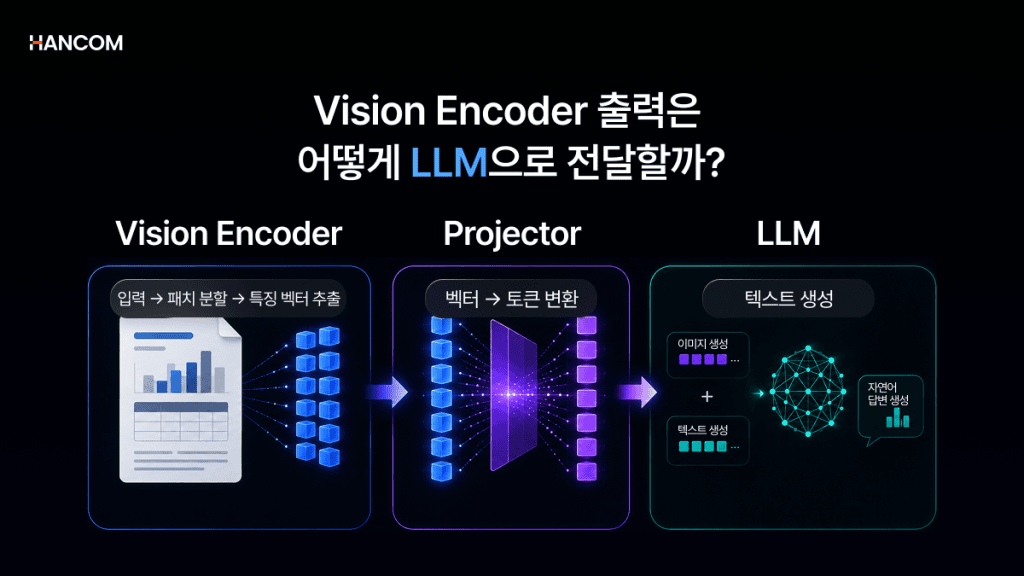
비전 인코더(Vision Encoder) 출력이 LLM과 어떻게 연결될까
VLM의 구조는 비전 인코더, 프로젝터, LLM 세 요소로 구성되며, 이미지 정보는 이 경로를 거쳐 LLM이 처리할 수 있는 형태로 변환됩니다.
비전 인코더의 역할
비전 인코더(Vision Encoder)는 이미지를 작은 패치(patch)로 분할한 뒤 각각을 벡터로 인코딩해 시각적 특징 벡터(Visual Feature Vectors)를 출력합니다. 트랜스포머 구조를 이미지 처리에 적용한 ViT(Vision Transformer)가 대표적입니다.
이미지 정보를 변환하는 프로젝터(Projector)
비전 인코더 출력을 LLM이 이해할 수 있는 이미지 토큰으로 변환하는 역할을 합니다. 구현 방식에 따라 선형 투영층(Linear Projection), 교차 어텐션(Cross-Attention) 등이 사용됩니다.
LLM의 역할
텍스트를 생성하는 대형 언어 모델인 LLM은 프로젝터가 변환한 이미지 토큰(Image Token)과 텍스트 토큰을 함께 입력받아 자연어 답변을 생성합니다. 오픈소스 VLM의 경우 사전학습된 LLM을 그대로 유지하면서 비전 인코더를 연결하는 방식이 많이 사용됩니다.
VLM이 필요한 이유, LLM의 한계와 문서 AI 문제
LLM의 이미지 및 문서 처리 한계
텍스트만 처리하는 LLM은 문서 안의 이미지, 차트, 표 같은 시각 정보를 의미 있는 데이터로 이해하는 데 한계가 있습니다. 문서 내 서식, 표, 그림처럼 텍스트로 표현되지 않는 정보는 LLM이 직접 해석하기 어렵고, 별도의 이미지 처리 과정 없이 텍스트만 입력하면 시각 정보가 누락될 수 있어요.
문서 파싱 과정에서 발생하는 구조 손실 문제
PDF·HWP·HWPX 문서에서 텍스트만 추출해 AI에 입력하면, 표·문단·레이아웃 같은 구조 정보가 함께 손실될 수 있습니다. 병합 셀 구조가 깨지거나 다단 레이아웃의 읽기 순서가 뒤섞이는 문제가 대표적이에요. 이미지·차트에 담긴 맥락 정보도 이 과정에서 사라지는 경우가 많습니다.
멀티모달 접근이 필요한 이유
텍스트 기반 LLM만으로는 문서 안의 시각 정보를 온전히 이해하기 어렵습니다. 사람이 문서를 읽을 때 레이아웃이나 그림을 함께 살펴보며 텍스트를 해석하듯, AI도 텍스트 외의 시각 정보를 함께 이해할 수 있어야 합니다. 이에 따라 이미지와 언어를 함께 처리하는 멀티모달 접근이 문서 AI의 핵심 과제로 떠오르고 있습니다.
VLM과 OCR, LLM의 차이 비교
OCR과 VLM 차이는 텍스트 인식 vs. 이미지 이해
OCR(Optical Character Recognition, 광학 문자 인식)은 이미지 속 글자를 인식해 텍스트로 변환하는 기술이고, VLM은 이미지 전체의 시각 정보와 맥락을 이해해 언어로 설명하는 기술입니다.
OCR은 ‘이 이미지에 어떤 글자가 있는가’를 추출하지만, VLM은 ‘이 이미지가 무엇을 의미하는가’를 해석합니다. 매출 그래프 이미지에서 OCR은 축 레이블 텍스트만 읽지만, VLM은 텍스트를 읽는 것을 넘어 ‘3분기 매출이 전분기 대비 증가한 막대그래프’라고 맥락까지 설명합니다.
📚 함께 읽으면 좋은 글
👉OCR이란? AI OCR 핵심 기술부터 문서 자동화 활용 가이드까지
LLM vs. VLM 차이는 텍스트 전용 vs. 멀티모달
텍스트만 입력받는 LLM과 달리, 이미지와 텍스트를 함께 입력받는 VLM은 시각 정보와 언어 정보를 통합해 처리하는 멀티모달 모델입니다.
한눈에 살펴보는 OCR, LLM, VLM 비교
| 구분 | OCR | LLM | VLM |
| 입력 | 이미지 | 텍스트 | 이미지+텍스트 |
| 처리 방식 | 문자 인식 | 언어 이해, 생성 | 시각, 언어 통합 이해 |
| 출력 | 추출 텍스트 | 텍스트 | 추출 텍스트, 이미지 설명, 질문 답변 |
| 이미지 이해 | 미지원 | 미지원 | 지원 |
기존 컴퓨터 비전 모델과의 차이
학습된 특정 작업만 수행하는 기존 컴퓨터 비전 모델과 달리, VLM은 자연어 지시로 다양한 시각적 작업에 유연하게 대응합니다.
다만 객체 탐지·분할 같은 특화 작업에서는 전용 CV 모델이 더 높은 정확도를 보이는 경우도 있습니다.
기존 CV 모델의 한계
분류(Classification), 객체 탐지(Object Detection), 분할(Segmentation) 같은 기존 컴퓨터 비전 모델은 학습된 특정 작업을 정확하고 효율적으로 수행하도록 설계되어 있습니다. 좁은 범위의 작업에서는 높은 성능을 보이지만, 새로운 작업을 추가하려면 별도 학습 데이터와 파인튜닝이 필요합니다.
VLM의 확장성
VLM은 작업을 자연어 지시로 정의합니다. 그로 인해 이미지 캡셔닝, 문서 이해, 차트 해석 등 폭넓은 작업을 하나의 모델로 처리할 수 있습니다. 문서 인식 분야에서도 OCR·레이아웃 분석·정보 추출을 개별 모델로 연결할 필요 없이, 이미지에서 텍스트와 표, 키-값을 한 번에 얻을 수 있어 파이프라인이 단순해지고 단계별 오류 전파가 크게 줄어듭니다.
문서 AI에서 VLM의 한계와 데이터 전처리의 중요성
VLM이 잘 동작하지 않는 이유는 데이터 품질 문제
VLM 성능 자체도 중요하지만, 실제 프로덕션 환경에서는 입력 데이터의 구조적 품질이 결과에 큰 영향을 미치는 경우가 많습니다.
아무리 정교한 VLM 모델을 사용해도 문서에서 추출된 데이터의 구조가 무너져 있으면 정확한 결과를 낼 수 없습니다. 문서 구조 정보 없이 텍스트만 입력되면, VLM은 이 내용이 제목인지 본문인지, 표의 어느 셀에 속하는지를 파악하기 어렵죠.
문서 구조가 깨지면 왜 AI 성능이 떨어질까
표의 셀 관계, 문단 계층, 이미지와 텍스트의 위치 관계가 손실된 상태로 VLM에 입력되면, 모델이 문서 안의 의미 관계를 안정적으로 해석하기 어려워질 수 있습니다.
예를 들어 ‘3분기 실적’ 제목 아래 매출 표가 있는 문서를 구조 없이 단순 텍스트로 변환하면, 제목과 표 사이의 관계 정보가 약해질 수 있습니다.
RAG 파이프라인에서도 구조가 누락된 텍스트 일부만 검색될 경우, 문맥 연결이 불안정해지면서 부정확한 답변이나 할루시네이션이 발생할 가능성이 높아집니다.
문서 데이터 품질이 AI 결과에 미치는 영향
VLM은 이미지와 텍스트를 함께 처리하는 멀티모달 모델인 만큼, 입력 문서의 구조와 맥락에 대한 품질이 결과 정확도에 영향을 줄 수 있습니다.
특히 HWP·HWPX, PDF, 이미지가 혼합된 복잡한 문서는 표 구조·문단 계층·이미지 위치 관계까지 유지한 상태로 추출하는 과정이 중요합니다.
제목과 본문 관계, 표의 행·열 구조, 이미지 주변 설명 같은 맥락 정보가 유지되어야 VLM과 LLM도 문서를 더 자연스럽게 해석할 수 있습니다.

문서를 이해 가능한 AI 데이터로, 한컴 데이터 로더
한컴 데이터 로더는 문서 AI 시스템의 전처리 문제를 해결하는 문서 구조 분석(DLA, Document Layout Analysis) 솔루션입니다.
문서 구조 손실 문제를 해결합니다. HWP·HWPX의 원본 바이너리 직접 파싱을 통해 데이터 손실 없이 메타데이터를 보존합니다.
표, 다단 레이아웃을 유지합니다. 병합 셀, 테두리 없는 표, 다단 레이아웃의 읽기 순서까지 원본 구조를 보존해 셀 단위로 추출합니다. VLM이나 LLM에 입력했을 때 행·열 관계가 그대로 전달됩니다.
텍스트와 객체 관계를 보존합니다. 문서 레이아웃 분석 기술인 문서 구조 분석(DLA)으로 텍스트와 이미지, 차트의 위치 관계를 파악합니다. 또한 VLM 기반 이미지 캡셔닝 기술을 활용해 이미지를 텍스트 설명으로 변환하는 파이프라인을 지원합니다. (해당 기능은 현재 PoC 단계로, 상용 출시 일정은 추후 안내될 예정입니다)
비정형 문서를 데이터화합니다. 스캔 문서, 이미지가 포함된 PDF, 복잡한 레이아웃의 HWP·HWPX까지 문서 유형과 제품 구성에 따라 JSON 등 구조화된 형태로 출력되어, AI 학습 데이터 준비 및 RAG 파이프라인 연결에 활용할 수 있습니다.
💡 VLM, RAG 파이프라인 구축 전, 문서 전처리 품질부터 점검해 보세요.
VLM 자주 묻는 질문 FAQ
Q1. VLM은 LLM과는 어떤 차이가 있나요?
VLM은 이미지와 텍스트를 함께 처리하는 멀티모달 AI 모델입니다. 텍스트 중심으로 동작하는 기존 LLM과 달리, 이미지 입력까지 함께 처리해 시각 정보와 텍스트 관계를 기반으로 답변을 생성할 수 있습니다.
Q2. 문서 파싱과 OCR의 차이가 무엇인가요?
OCR은 이미지 속 글자를 텍스트로 변환하는 기술이고, 문서 구조를 분석하는 파싱(Parsing)은 문서 전체의 구조, 계층, 의미 관계를 구조화 데이터로 변환합니다. OCR이 무엇이 적혀 있는지를 읽는다면, 파싱은 어떤 구조로 배치되어 있는지를 분석하는 데 초점이 있습니다.
Q3. AI한테 문서 읽히려면 왜 파싱을 따로 해야 하나요?
AI는 단순 텍스트보다 문단 계층, 표 구조, 위치 관계가 유지된 데이터에서 문맥을 더 안정적으로 처리할 수 있습니다. 문서를 단순 복사·붙여넣기 방식으로 입력하면 표 구조가 깨지거나 이미지 맥락 정보가 함께 손실될 수 있습니다. 문서 파싱은 이런 구조 정보를 유지한 상태로 AI가 활용할 수 있도록 변환하는 전처리 과정입니다.
VLM 시대, 문서 데이터 품질이 AI 성능을 좌우합니다
🖥️한컴 데이터 로더
VLM과 멀티모달 AI가 발전할수록, 입력 데이터 품질이 AI 성능의 실질적 경계가 됩니다. 고성능 모델보다 올바른 데이터를 공급하는 전처리 파이프라인이 먼저입니다.
한컴 데이터 로더는 HWP·HWPX·PDF·OOXML을 구조화해 RAG 파이프라인 연결에 활용할 수 있는 고품질 데이터를 만듭니다. 에이전트가 신뢰할 수 있는 문서 전처리, 한컴 데이터 로더로 시작해 보세요.